This walkthrough is also available as a Jupyter ipynb Notebook - you can run yourself
Let's say that you have a dataset that you would like to quickly understand.
The point of this doc is to walk through how:
- to access an example dataset
- massage the data to something easier to work with
- group and aggregate the data
- display a table of the results
- show a chart
Assumptions
The How to Use navbar tutorial talks about what Jupyter Notebooks are - a REPL format that intermixes code (and or their results) with markdown/text blocks to provide context.
It also talks about how to install Jupyter, and the iJavaScript language kernel to provide JavaScript language support.
While there are some amazing other options for using notebooks:
- ObservableHQ - a jupyter like experience working with javascript out of the box
- Visual Studio Code - now has direct support for Jupyter Notebooks ...
We will assume you have:
- Jupyter Lab installed
- iJavaScript kernel installed
- npm install jupyter-ijavascript-utils - in the directory you launched Jupyter Lab
- Jupyter Lab running - (by running the command
Jupyter Lab)
Please see the How to Use navbar tutorial for details.
Require libraries in the Notebook
Jupyter (unlike ObservableHQ) works in a top down order of evaluation, so to use the jupyter-ijavascript-utils library,
Lets include a cell at the top with our require statements.
utils = require('jupyter-ijavascript-utils');
//-- any other imports
'Libraries successfully imported';
(Executing the cell, through the ▷ icon will render Libraries successfully imported underneath)
Variable Scope
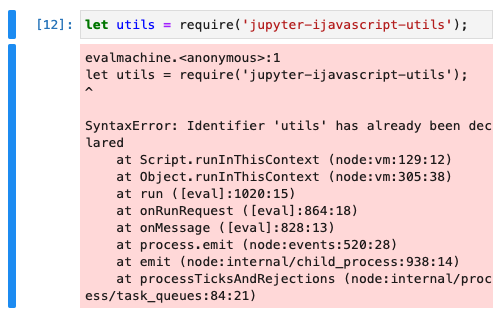
We did not use let or const when defining the variable
This puts the variable in the global / document scope.
You can absolutely use let, const, var, etc. to define your variables, but this will cause a problem if you execute your cell again at any time.
This will throw an error as the variable cannot be redefined.
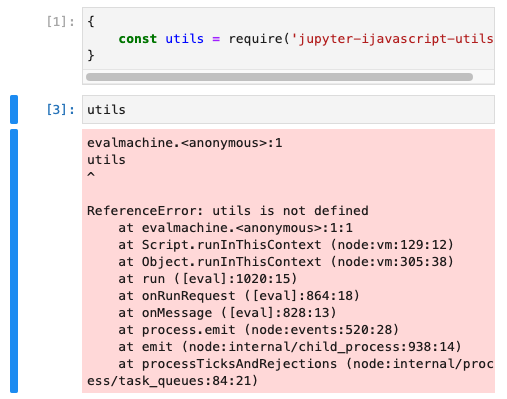
Another option is to use a {} scope block for the cell.
This will not throw an error, but it will however not make the variable available for the next cell.
Return Value of a Cell
Note that we included a string at the end of the cell:
'Libraries successfully imported';
The last value accessed in a cell is by default passed as the result of the cell.
(You can do this manually by running the command $$.sendResult('this is the return value');)
If you do not include this statement, the iJavaScript will attempt to convert the last value to JSON, and this can cause quite a bit of scrolling.
For cells where we care more about the side effects of running the cell
(i.e. there is no result we want, Consider putting a descriptive string, and collapsing the code)
Adding in a Text Node
Next lets add in a Text Node, to help us remember where our code starts:
Click the + button in the toolbar to make a new cell.
Enter the following:
# Gap Minder DataSet
This time, change the dropdown in the toolbar from Code to Text
Note that the cell turns BLUE.
(Executing the cell, through the ▷ icon will render the text out as a header)
Accessing a Sample Dataset
The Vega team has a Sample Datasets library
The jupyter-ijavascript-utils library references it, so you can get sample data quickly.
We can see the list of the datasets available:
utils.datasets.list();
// [
// 'annual-precip.json',
// 'anscombe.json',
// 'barley.json',
// 'budget.json',
// 'budgets.json',
// 'burtin.json',
// ...
// ]
The DataSet we want is the facinating GapMinder Life Expectancy study
$$.async()
utils.datasets.fetch('gapminder.json')
.then(data => {
gapMinder = data;
$$.sendResult(`captured gap minder records: ${gapMinder.length}`);
});
// 'captured gap minder records: 693'
As we called $$.async() - the cell knows that it should pause execution for the next cell until $$.sendResult(...) is called.
Note - the utils.ijs.await method available in the library can simplify this call, to support await.
//-- does the same thing as the cell above
utils.ijs.await(async ($$, console) => {
gapMinder = await utils.datasets.fetch('gapminder.json');
return `captured gap minder records: ${gapMinder.length}`;
});
// 'captured gap minder records: 693'
See the ijs.await() docs for more.
Understanding the Data
One option to understand the kinds of data is to always look at the first record:
gapMinder[0];
// gives:
// {
// year: 1955,
// country: 'Afghanistan',
// cluster: 0,
// pop: 8891209,
// life_expect: 30.332,
// fertility: 7.7
// }
The Utilities also include two additional methods that can help:
object.generateSchema(object | array)
This generates a schema of all objects in the collection, and of the objects those contain (deep introspection),
It tells us that there are no objects further down with additional fields, and all the fields are always populated.
But this can leave a bit to be desired for the types of properties.
// {
// '$schema': 'http://json-schema.org/draft-04/schema#',
// type: 'array',
// items: {
// type: 'object',
// properties: {
// year: [Object],
// country: [Object],
// cluster: [Object],
// pop: [Object],
// life_expect: [Object],
// fertility: [Object]
// },
// required: [ 'year', 'country', 'cluster', 'pop', 'life_expect', 'fertility' ]
// }
// }
object.getObjectPropertyTypes(object / array)
This identifies the types of properties much clearer, but only of the objects in the collection (shallow introspection).
utils.object.getObjectPropertyTypes(gapMinder)
// returns
// Map(2) {
// 'number' => Set(5) { 'year', 'cluster', 'pop', 'life_expect','fertility' },
// 'string' => Set(1) { 'country' }
// }
Simple Aggregation
A few fields come out that seem interesting:
- Year (number)
- cluster (number)
- pop - population (number)
- life_expect - life expectancy (number)
- fertility - number
- country - string
I'd like to understand what kind of values are shown in cluster
utils.aggregate.unique(gapMinder, 'cluster');
// [ 0, 3, 4, 1, 5, 2 ]
or which countries are covered:
utils.aggregate.unique(gapMinder, 'country')
// [
// 'Afghanistan', 'Argentina', 'Aruba',
// 'Australia', 'Austria', 'Bahamas',
// ...
// ]
how many countries:
utils.aggregate.unique(gapMinder, 'country').length
// 63
utils.aggregate.distinct(gapMinder, 'country');
// 63
Or maybe I would like to know the extents for multiple fields:
({
year_range: utils.agg.extent(gapMinder, 'year'),
pop_range: utils.agg.extent(gapMinder, 'pop'),
life_expect: utils.agg.extent(gapMinder, 'life_expect'),
fertility: utils.agg.extent(gapMinder, 'fertility')
});
// returns
// {
// year_range: { min: 1955, max: 2005 },
// pop_range: { min: 53865, max: 1303182268 },
// life_expect: { min: 23.599, max: 82.603 },
// fertility: { min: 0.94, max: 8.5 }
// }
Group Transformations
(See module:aggregate and module:group.by for more...)
Let's take a closer look at the cluster field:
utils.group.by(gapMinder, 'cluster')
.reduce((records) => ({
countries: utils.agg.unique(records, 'country')
}))
it looks like they are geography regions:
// [
// {
// cluster: 0,
// countries: [ 'Afghanistan', 'Bangladesh', 'India', 'Pakistan' ]
// },
// {
// cluster: 3,
// countries: [
// 'Argentina', 'Aruba', 'Bahamas', 'Barbados', 'Bolivia',
// 'Brazil', 'Canada', 'Chile', 'Colombia', 'Costa Rica',
// 'Cuba', 'Dominican Republic', 'Ecuador', 'El Salvador',
// 'Grenada', 'Haiti', 'Jamaica', 'Mexico', 'Peru', 'United States', 'Venezuela'
// ]
// },
// {
// cluster: 4,
// countries: [
// 'Australia', 'China', 'Hong Kong', 'Indonesia', 'Japan',
// 'South Korea', 'North Korea', 'New Zealand', 'Philippines'
// ]
// },
// ...
// ]
How many entries are there per country?
Let's group by country, and the the number of records and then sort descending by that count
utils.group.by(gapMinder, 'country')
.reduce((records) => ({
count: utils.agg.length(records)
}))
.sort(utils.array.createSort('-count'));
// provides
// [
// { country: 'Afghanistan', count: 11 },
// { country: 'Argentina', count: 11 },
// { country: 'Aruba', count: 11 },
// { country: 'Australia', count: 11 },
// { country: 'Austria', count: 11 },
// ...
// ]
Looks like they are 11 records all the way down.
Just to be sure, we can wrap the results with an extent:
utils.agg.extent(
//-- same query as before
utils.group.by(gapMinder, 'country')
.reduce((records) => ({
count: utils.agg.length(records)
}))
.sort(utils.array.createSort('-count'))
, 'count')
// provides { min: 11, max: 11 }
Accessing Groups Halfway
Note We can also pick halfway within a group.
For example, group by country and year but then get the groups by year for a country (Say, Afghanistan)
utils.group.by(gapMinder, 'country', 'year')
.get('Afghanistan');
//-- returns
// SourceMap(11) [Map] {
// 1955 => [
// {
// year: 1955,
// country: 'Afghanistan',
// cluster: 0,
// pop: 8891209,
// life_expect: 30.332,
// fertility: 7.7
// }
// ],
// 1960 => [
// {
// year: 1960,
// country: 'Afghanistan',
// cluster: 0,
// pop: 9829450,
// life_expect: 31.997,
// fertility: 7.7
// }
// ],
// ...
// }
Table
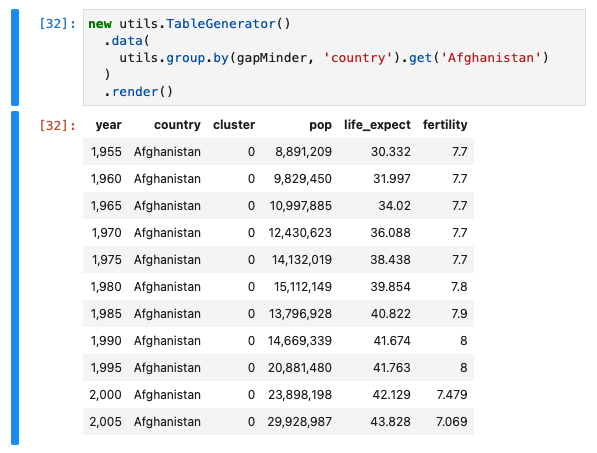
I think I'm quite interested to see how the data looks for Afghanistan.
Lets use the TableGenerator to make this easier to see.
new utils.TableGenerator()
.data(
utils.group.by(gapMinder, 'country').get('Afghanistan')
)
.render()
The TableGenerator#render will render the results right out to the Jupyter Notebook (generate as html and display it)
Note that there are a few other types of output, such as:
Like the Markdown table shown here:
| year | country | cluster | pop | life_expect | fertility |
|---|---|---|---|---|---|
| 1,955 | Afghanistan | 0 | 8,891,209 | 30.332 | 7.7 |
| 1,960 | Afghanistan | 0 | 9,829,450 | 31.997 | 7.7 |
| 1,965 | Afghanistan | 0 | 10,997,885 | 34.02 | 7.7 |
| 1,970 | Afghanistan | 0 | 12,430,623 | 36.088 | 7.7 |
| 1,975 | Afghanistan | 0 | 14,132,019 | 38.438 | 7.7 |
| 1,980 | Afghanistan | 0 | 15,112,149 | 39.854 | 7.8 |
| 1,985 | Afghanistan | 0 | 13,796,928 | 40.822 | 7.9 |
| 1,990 | Afghanistan | 0 | 14,669,339 | 41.674 | 8 |
| 1,995 | Afghanistan | 0 | 20,881,480 | 41.763 | 8 |
| 2,000 | Afghanistan | 0 | 23,898,198 | 42.129 | 7.479 |
| 2,005 | Afghanistan | 0 | 29,928,987 | 43.828 | 7.069 |
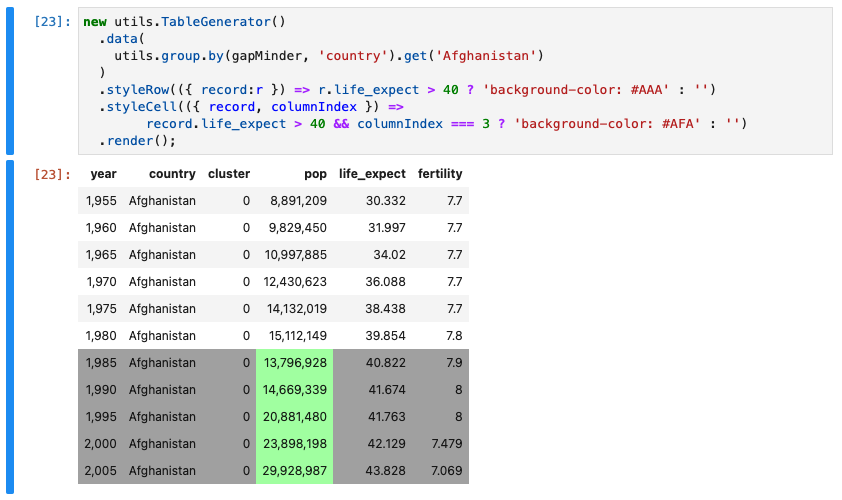
Styling a Table
Note that we can style the table if we'd like to show when the life expectancy rises above 40 years of age
new utils.TableGenerator()
.data(
utils.group.by(gapMinder, 'country').get('Afghanistan')
)
.styleRow(({ record:r }) => r.life_expect > 40 ? 'background-color: #AAA' : '')
.styleCell(({ record, columnIndex }) =>
record.life_expect > 40 && columnIndex === 3 ? 'background-color: #AFA' : '')
.render();
Adjusting the Table
While the table is helpful, lets clean it up a bit:
- hide the cluster column
- add in a new column for the continent
- make the year render as a string - ex: 1966
We'll do this through
- TableGenerator#data
- TableGenerator#augment
- TableGenerator#labels
- TableGenerator#formatter
- TableGenerator#columnsToExclude
continents = [
{ id: 0, continent: 'South Asia' },
{ id: 1, continent: 'Europe & Central Asias' },
{ id: 2, continent: 'Sub-Saharan Africa' },
{ id: 3, continent: 'Americas' },
{ id: 4, continent: 'East Asia & Pacific' },
{ id: 5, continent: 'Middle East & North Africa' }
];
clusterMap = utils.group.index(continents, 'id');
// map of contents with the id field as the key
new utils.TableGenerator()
.data(
utils.group.by(gapMinder, 'country').get('Afghanistan')
)
//-- add new field / column
.augment({
continent: (r) => clusterMap.get(r.cluster).continent
})
//-- labels
.labels({ pop: 'population', life_expect: 'life expectancy'})
//-- format a specific value, say a year to a String
.formatter({
year: (val) => String(val)
})
.columnsToExclude(['cluster'])
//-- or you could explicitly set the columns and order
// .columns(['year', 'continent', 'country', 'pop', 'life_expect', 'fertility'])
.render();
| year | country | population | life expectancy | fertility | continent |
|---|---|---|---|---|---|
| 1955 | Afghanistan | 8,891,209 | 30.332 | 7.7 | South Asia |
| 1960 | Afghanistan | 9,829,450 | 31.997 | 7.7 | South Asia |
| 1965 | Afghanistan | 10,997,885 | 34.02 | 7.7 | South Asia |
| 1970 | Afghanistan | 12,430,623 | 36.088 | 7.7 | South Asia |
| 1975 | Afghanistan | 14,132,019 | 38.438 | 7.7 | South Asia |
| 1980 | Afghanistan | 15,112,149 | 39.854 | 7.8 | South Asia |
| 1985 | Afghanistan | 13,796,928 | 40.822 | 7.9 | South Asia |
| 1990 | Afghanistan | 14,669,339 | 41.674 | 8 | South Asia |
| 1995 | Afghanistan | 20,881,480 | 41.763 | 8 | South Asia |
| 2000 | Afghanistan | 23,898,198 | 42.129 | 7.479 | South Asia |
| 2005 | Afghanistan | 29,928,987 | 43.828 | 7.069 | South Asia |
Bake in the Continent
To avoid constantly mapping the continent, lets just bake the continent right into the record.
continents = [
{ id: 0, continent: 'South Asia' },
{ id: 1, continent: 'Europe & Central Asias' },
{ id: 2, continent: 'Sub-Saharan Africa' },
{ id: 3, continent: 'Americas' },
{ id: 4, continent: 'East Asia & Pacific' },
{ id: 5, continent: 'Middle East & North Africa' }
];
clusterMap = utils.group.index(continents, 'id');
// map of contents with the id field as the key
//-- overwrite with an immutible update
gapMinder = utils.object.augment(gapMinder, (record) => ({
continent: clusterMap.get(record.cluster).continent
}));
alternatively, you can write in place
//-- does the same thing
utils.object.augment(gapMinder, (record) => ({
continent: clusterMap.get(record.cluster).continent
}), true);
Charts
While we can show more columns in tables, charts can show information much more compactly.
(See the Vega module for more...)
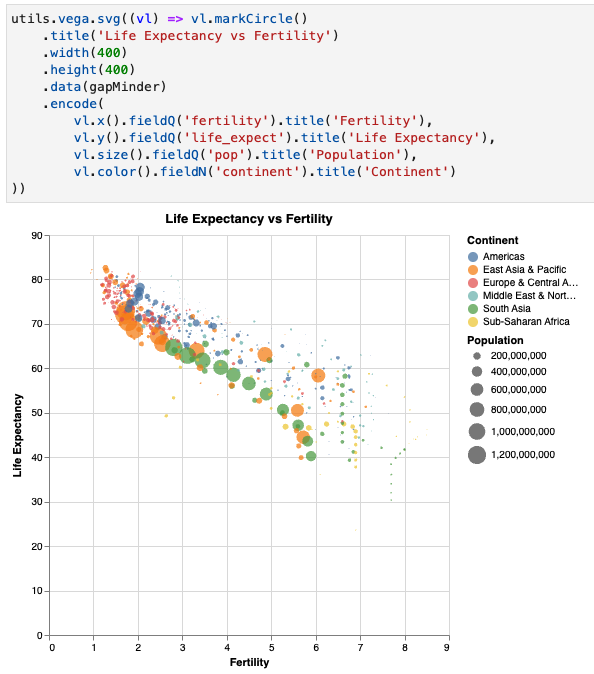
Lets go with a common topic, life expectancy vs fertility (reproduction) rates.
We would like:
- x position of the point to be the Fertility Rate
- y position to be the life expectancy
- color to be based on the continent
- and maybe size to show population.
Note that this translates to vega fairly well...
One item of note:
- fieldQ - means a Quantitative (Number) field
- fieldN - means a Nominal (Categorical / Non-Number) field
utils.vega.svg((vl) => vl.markCircle()
.title('Life Expectancy vs Fertility')
.width(400)
.height(400)
.data(gapMinder)
.encode(
vl.x().fieldQ('fertility').title('Fertility'),
vl.y().fieldQ('life_expect').title('Life Expectancy'),
vl.size().fieldQ('pop').title('Population'),
vl.color().fieldN('continent').title('Continent')
))
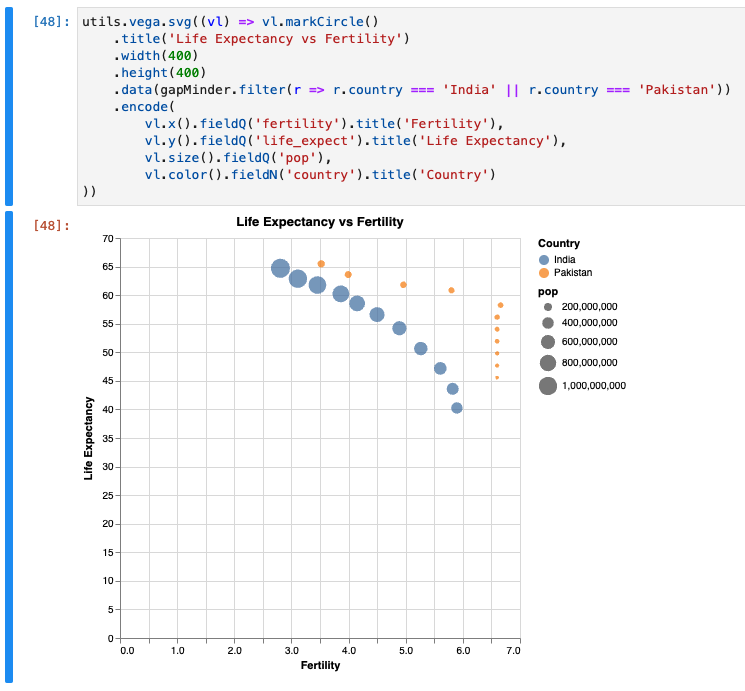
We could filter to specifically a continent directly on the data.
utils.vega.svg((vl) => vl.markCircle()
.title('Life Expectancy vs Fertility')
.width(400)
.height(400)
.data(gapMinder.filter(r => r.country === 'India' || r.country === 'Pakistan'))
.encode(
vl.x().fieldQ('fertility').title('Fertility'),
vl.y().fieldQ('life_expect').title('Life Expectancy'),
vl.size().fieldQ('pop'),
vl.color().fieldN('country').title('Country')
))
Aggregate Charts
One item to note is that Vega does not allow for multiple series on the same object. (At least to my understanding)
Meaning, if we have a record like the following:
new utils.TableGenerator(utils.group.by(gapMinder, 'country')
.reduce((records) => ({
minPopulation: utils.agg.min(records, 'pop'),
maxPopulation: utils.agg.max(records, 'pop'),
avgPopulation: utils.agg.avgMean(records, 'pop'),
})))
.renderMarkdown()
| country | minPopulation | maxPopulation | avgPopulation |
|---|---|---|---|
| Afghanistan | 8,891,209 | 29,928,987 | 15,869,842.455 |
We would need to separate out to multiple records to show both the min, average and mean values.
something like this:
| country | _aggregateKey | _aggregateValue |
|---|---|---|
| Afghanistan | minPopulation | 8,891,209 |
| Afghanistan | maxPopulation | 29,928,987 |
| Afghanistan | avgPopulation | 15,869,842.455 |
To achieve this, use reduceSeparate() - rather than reduce() as we have done so far:
new utils.TableGenerator(utils.group.by(gapMinder, 'country')
.reduceSeparate((records) => ({
minPopulation: utils.agg.min(records, 'pop'),
maxPopulation: utils.agg.max(records, 'pop'),
avgPopulation: utils.agg.avgMean(records, 'pop'),
})))
.renderMarkdown()
| country | _aggregateKey | _aggregateValue |
|---|---|---|
| Afghanistan | minPopulation | 8,891,209 |
| Afghanistan | maxPopulation | 29,928,987 |
| Afghanistan | avgPopulation | 15,869,842.455 |
| Argentina | minPopulation | 18,927,821 |
| Argentina | maxPopulation | 39,537,943 |
| Argentina | avgPopulation | 28,753,173 |
| Aruba | minPopulation | 53,865 |
| Aruba | maxPopulation | 71,566 |
| Aruba | avgPopulation | 62,591.455 |
This can be done with either:
Choropleth - Data Driven Maps
A choropleth is essentially a data driven map, that changes the map in some regard based on those values.
A very familiar example are the red and blue styles shading of states for US Elections, but can show many things such as precipitation, or heatmaps, and many other things.

See the Let's make a Data Driven Map on how you could build your own.
Further Reading
Very cool example of a chart done with Vega Lite on this topic
There are a growing list of libraries that are amazing for computational journalism, data science and others.
See this stackoverflow for someone asking why couldn't Numpy be written in JavaScript;
D3
D3, specifically: group / rollup and flatGroup / flatRollup
DanfoJS
DanfoJS - a js library heavily inspired by Pandas so someone familiar with Pandas can get up to speed very quickly
DataFrame-JS
dataframe-js - provides an immutable data structure for DataFrames which allows to work on rows and columns with a sql and functional programming inspired api.
StandardLib
StdLib - is a great library that compiles down to C/C++ level to providespeeds comparable to Numpy.
NumJS
NumJS is also a great number processing library. It may not be as fast as StdLib, but it can sometimes be easier touse.