This walkthrough is also available as a Jupyter ipynb Notebook - you can run yourself
Jupyter Notebooks have a fairly elegant architecture, with a number of related projects working together to provide an executable notebook.
Here we'll focus on how the iJavaScript Kernel interacts with Jupyter. However, there are resources provided throughout for learning more.
Available as Notebook
Please note that this is also available as a Jupyter Notebook, which is how many of the diagrams created where generated (using PlantUML through the jupyter-ijavascript-utils library)
For example using homebrew or simply running from the jar file
PlantUML PicoWeb
If you wish to run this yourself, please note you'll need to run or specify a PlantUML Server - but this is quite easy through PlantUML PicoWeb)
This can be as easy as running the following in another tab:
# ex - like through homebrew
plantuml -picoweb
# ex - like through the jar
java -jar plantuml.jar -picoweb
Some diagrams (such as Class and Object) may depend on graphviz, but bypassed if using the layout smetana)
Please see this document on PlantUML and GraphViz for more, including how to install
utils = require('jupyter-ijavascript-utils');
['utils']
[ 'utils' ]
Jupyter History
Project Jupyter is a community with the goal to 'develop open-source software, open-standards, and services for interactive computing across dozens of programming languages'
Originally, it was a spin-off project from IPython and a reference to:
- the three core languages supported: Julia, Python and R
- but also a homage to Galileo's notebooks in discovering the moons of jupyter.
Kernel Architecture
The Jupyter Kernels are a language specific process that run independently from Jupyter and interact through messaging to the Jupyter Applications and interfaces.
There are two types of Kernels:
- Native Kernels
- Manage Language Execution, and provide a response
- Manage Notebook JSON
- Process ØMQ Messaging
- Wrapper Kernels
- Manage Language Execution, and provide a response
- Rely on IPython's API to
- Manage IPython JSON
- Manage ØMQ Messaging to cells

Wrapper Kernels are much easier to write, as they implement only the core Language Execution
Each Kernel provides a running instance of node (and variables), that can then be accessed by subsequent cells.

Kernel Management
Within Jupyter, we have a list of Kernels that are currently 'running' (active) - each providing a running instance that the code is executing within.
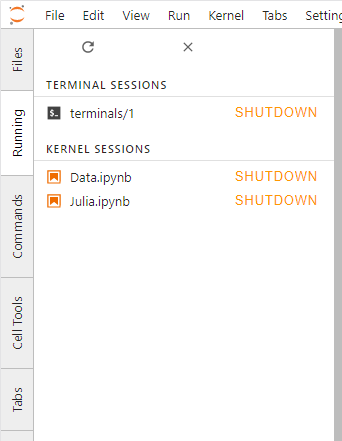
When a document is initially run (and there is no running instance for that document), then one is instantiated.
Jupyter Lab is managing those instances, and they can be killed at will.
Although there are some advanced topics for exceptions, generally each document has their own kernel instance

Mime Types
The iJavaScript Kernel - and Jupyter Lab in general, supports rendering results in multiple types of formats:
- $$.text - renders out results as Plain Text
- $$.html - renders out results as HTML
- $$.svg - renders out results as SVG
- $$.png - renders out results as PNG
- $$.jpeg - renders out results as JPEG
- $$.mime - lets you specify the mime type the results should be shown
See the docs for more.
This can be quite helpful, as NPM Modules can generate the SVG Code, and then render them using one of those mime types.
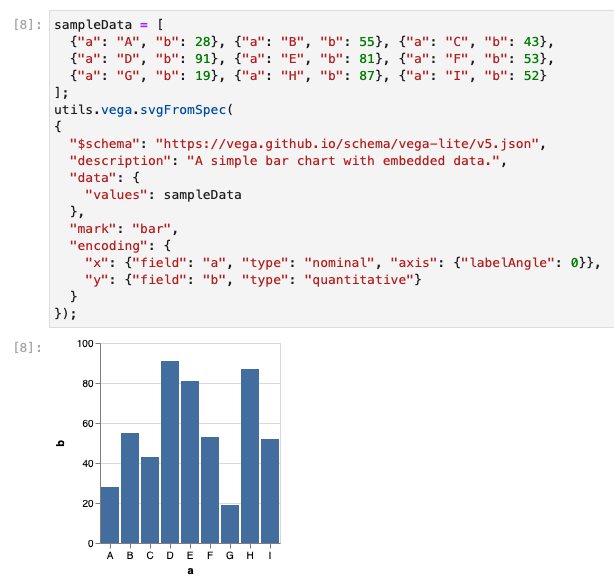
Dynamic HTML
Note that this is not like a typical webpage, where the entire document must be executed.
Note that with the page as multiple cells, we have control over the order that the cells are executed.
We can pick and choose one specific cell, all cells after a specific point, etc.
The results are then injected into the DOM through dynamic html / javascript directly underneath the 'cell contents' - as 'cell results'
HTML Script
This brings us to the HTML Script concept of Browser - Server division of labor.
(Yes I know the name is irritating :) - we are welcome to suggestions)
Normally, Jupyter Lab manages replacing the 'cell results' with the response from the Kernel.
Although it was not always the case, it appears that the response from the server can only be returned once per execution.
(Slight Note: console.log() requests can be called multiple times, and appended in real time)
This means that Animations are typically impossible, because the server can only dynamically update the html results once.
We CAN do animations though with HTML Script calls
In this case, we are returning back html, that also has JavaScript executed on the client side upon render.
We can also leverage a number of other techniques to serialize NodeJS functions, code and data - and pass them to the browser (client side).
The utils.ijs.htmlScript() method generates html that is then executed on the client once the dynamic html is rendered. (Such as loading scripts from a CDN, and the NodeJS script that will be converted and passed to the client to run when all dependencies have been loaded)
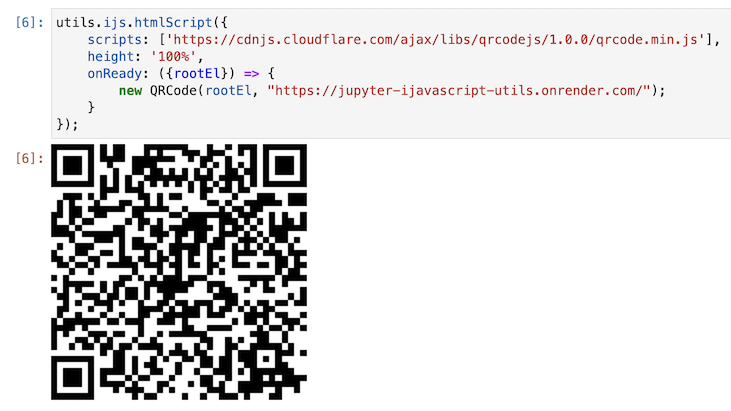

HTMLScript takes care of writing the HTML code to be run on the client and simply rendered with the HTML mime type.
At this point it is very similar to developing an html page, but one that can be leveraged again and again in its own isolated environment.
(Note: we are still working on leveraging ShadowRoots for the results - see Issue #2)
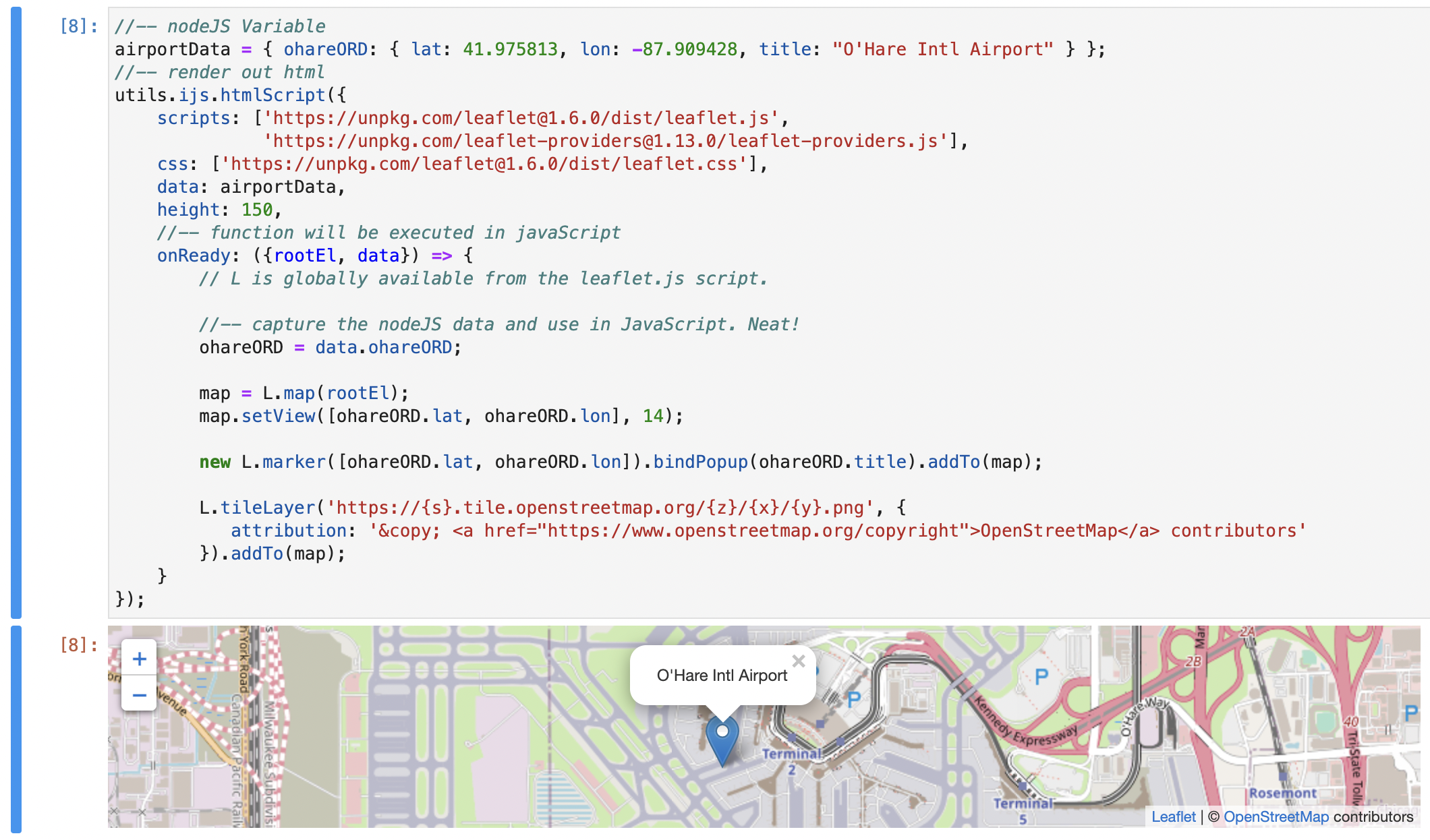
(See the jupyter-ijavascript-utils leaflet module for more)
Asynchronous Requests
Please note that the use of Asynchronous Requests is very common.
The utils.ijs.await was intended to simplify the use of await until it has full support in the kernel.
Await allows for synchronous coding when working with asynchronous promises.
To leverage await in Javascript, it requires:
- an
async functionthat then contains theawaitcommands - a promise that we would then await on
- a top level call to that async function
For example:
//-- provides a promise
function resolveAfter2Seconds(x) {
return new Promise(resolve => {
setTimeout(() => {
resolve(x);
}, 2000);
});
}
//-- async method
async function f1() {
//-- capture the promise
const promiseToResolve = resolveAfter2Seconds(10);
//-- await on the promise
var x = await promiseToResolve;
//-- synchronous call that will ONLY be executed 2 seconds after the previous line
console.log(x); // 10
}
f1();
iJavaScript await
The iJavaScript kernel currently only behaves asynchronously if told that it should wait until $$.sendResult() is called.
For example:
//-- tell this cell that it should not continue until sendResult is called
$$.async()
//-- provides a promise
function resolveAfter2Seconds(x) {
return new Promise(resolve => {
setTimeout(() => {
resolve(x);
}, 2000);
});
}
//-- async method
async function f1() {
//-- capture the promise
const promiseToResolve = resolveAfter2Seconds(10);
//-- await on the promise
var x = await promiseToResolve;
//-- synchronous call that will ONLY be executed 2 seconds after the previous line
console.log(x); // 10
//-- tell the jupyter it is safe to run the next cell.
$$.sendResult(x);
}
f1();
Instead we can replace all this code with utils.ijs.await
utils.ijs.await(async($$, console) => {
console.log('before 2 seconds');
await utils.ijs.asyncWait(2);
console.log('after 2 seconds');
});
This can be very helpful for when loading in data from external sources.
utils.ijs.await(async($$, console) => {
const connection = new jsforce.connection(...);
accounts = await connection.query('select id from accounts limit 100');
contacts = await connection.query('select id from contacts limit 100');
console.log('we have ${accounts.length} accounts and ${contacts.length} contacts');
});
and then leverage those values asynchrnously retrieved on the following cells, even though they are synchronously written.
//-- still works
console.log('we have ${accounts.length} accounts and ${contacts.length} contacts');
For more information, please see the utils.ijs.await function